

What are Diffusion Models? 🤔
In this article, we will explore the concept of diffusion models and how they can be used to enhance the quality of samples generated by…

In this article, we will explore the concept of diffusion models and how they can be used to enhance the quality of samples generated by VAEs (and GANs).
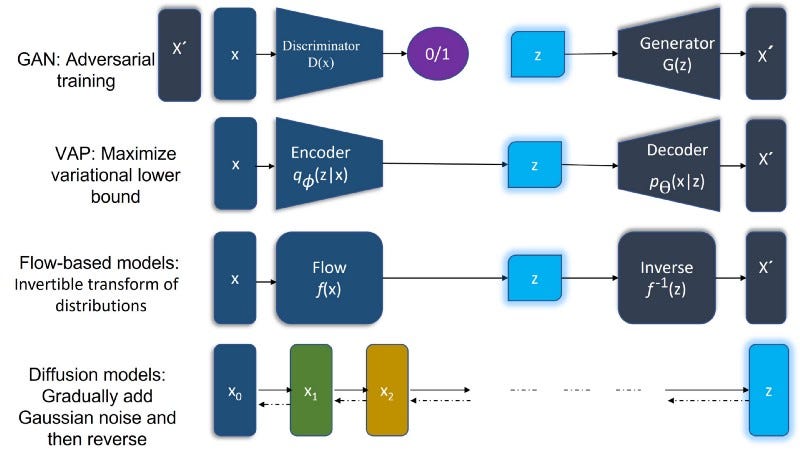
Diffusion models are a class of generative models that make use of latent variables. They have many applications, including VAEs and GANs (GANs are Generative Adversarial Networks).
The basic idea behind a diffusion model is to use the relationship between two features as input into an existing training set to generate new data points; this process can be repeated thousands or millions of times over until you get something close enough to what you want.
GANs and VAEs use latent variables which can be considered as a set of related data points (e.g., an image). In order for these latent variables to be used effectively in generating images and videos, they need to be updated regularly with new information about their appearance. This process is called “training” or “supervised learning”.
Diffusion models can be used during training/supervised learning phases in order to get better results than those obtained through traditional methods such as random initialization schemes or gradient descent techniques; however, there are some disadvantages associated with using diffusion methods such as needing more training time compared with other less time-consuming approaches like SGD (Stochastic Gradient Descent)
“Diffusion model is a model for sampling from an intractable distribution by iteratively exploring a tractable space of probability measures” (*David Lopez-Paz, 2017*)
Diffusion models are designed to enhance the quality of samples generated by VAEs and GANs, but they’re still more computationally intensive than these two methods alone. In general, diffusion models are a generalization of the VAE model: rather than using a single distribution to generate values for each sample in your dataset — as VBZ does — you can instead consider many possible distributions over time (or multiple timescales) within each segmentation point in order to generate more natural-looking data points.
The idea behind diffusion models is to model the density functions for two different spaces with one simple process. The first space is the space of our data (i.e., images). The second space is represented by an easier-to-sample from latent space.
For example, consider a CNN trained on MNIST dataset: You can think of it as an array of pixels that represent each pixel in your image and then you have a list of features like location or scale which help you describe what kind of thing this pixel represents (e.g., “this one has some blue stuff in its background”). When I say “feature” here I mean something that’s extracted from your image, but sometimes we’ll also use them interchangeably when talking about a classifier that uses them instead! So let’s say we have another database — let’s call it Dog — where all dogs are represented by 28x28 gray-scale images where pixels are either white or black according to whether they’re wearing a collar around their neck…
The key takeaway from this article is that diffusion models are a great way to improve the quality of our generated samples. They allow us to generate more realistic crops while still using an easy-to-generate model (like GANs).